




Thank you all for the participating in the Galaxy Zoo: Weird & Wonderful project! We have successfully completed classification of all the subjects! A summary of the preliminary analysis is now available in the Results section of the About Page!
We are currently testing a new workflow for the next round of the project! Please ignore any active workflows!
Results
Dear all, we wanted to post some brief updates of our ongoing analysis of all the wonderful classifications and talk discussions you have provided recently on the Galaxy Zoo: Weird & Wonderful project. We were very excited to see the different kinds of unusual objects that you have found and tagged! Our investigations mainly involved assessing the identified unusual/interesting subjects along with their Talk-based tags with what the “unusualness” score that the machine learning model yields. Through this work, we aim to define pre-selection methods for future projects using large data sets such that a significant portion of “uninteresting” subjects can be omitted by preferentially selecting unusual/interesting subjects for effective and accelerated visual inspection.
There were approximately 24,800 subjects that at least 5 volunteers found to be interesting. We were quite pleased to see a wide variety of objects, such as some of the most spectacular galaxy mergers, gravitational lensing arcs, ringed galaxies, clumps, supernova candidates, asteroids, and even a few potential white dwarfs. Below is a collage of some example interesting things you have found!

Below, we show a distribution of subject tags split into two panels where the top shows more dominant ones while the bottom panel shows less-frequently used tags.
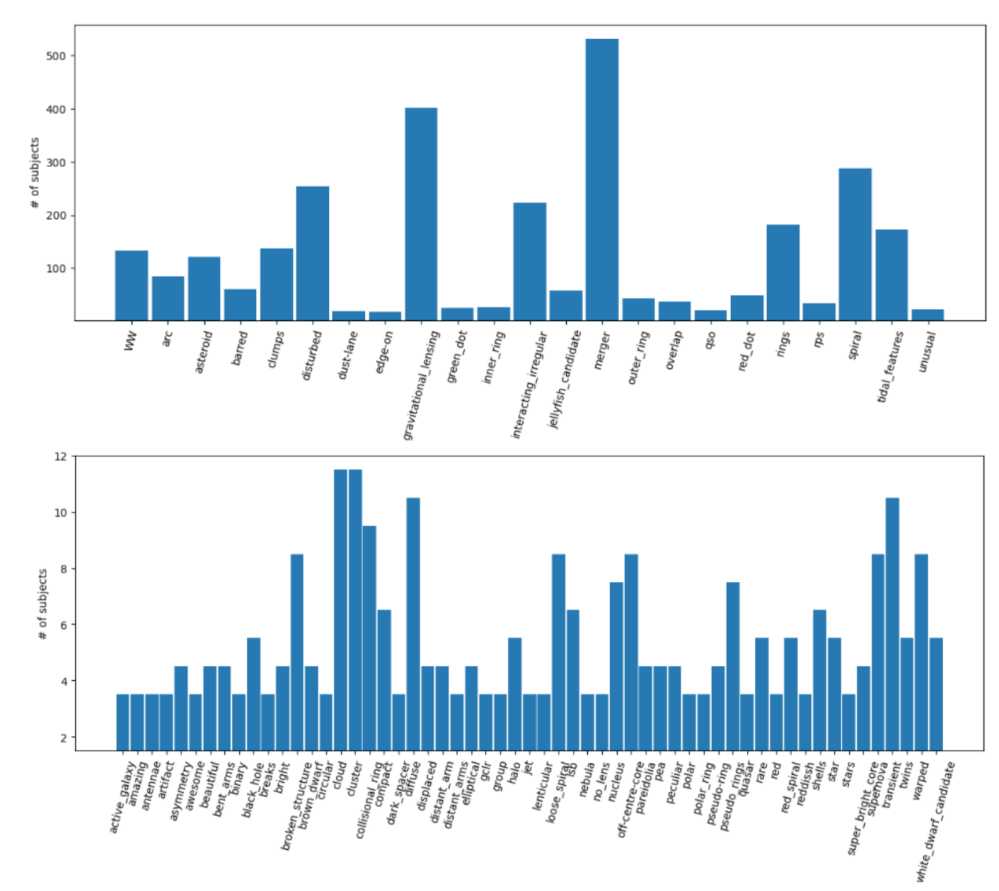
We looked at the relative distributions of the subjects by their talk tags and found that a more common set of categories such as galaxy mergers and rings had a generally higher fractional agreement on being interesting/unusual. On the other hand, rarer categories such as gravitational lens or arcs have a median agreement score that is smaller than the more common categories. This exercise highlighted to us to not omit subjects with low agreement scores as they might indeed correspond to rarer categories of interesting objects.
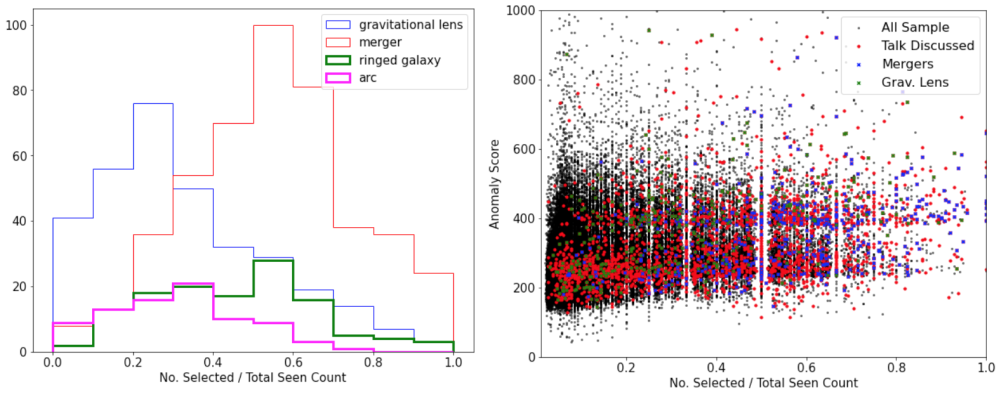
Additionally, we wanted to understand the relationship between volunteer identified unusual subjects and machine-based ones. As such, we analyzed the number of times a subject was chosen and the corresponding anomaly scores from our machine learning model. Interestingly, we found these quantities to be relatively uncorrelated, where the volunteer chosen subjects spanned the entire range of the machine anomaly scores without any obvious strong correlations. So it seems that humans and machines “think” differently about what might be considered strange.
In addition to the anomaly scores, our machine model can also produce a “latent space” for each subject image that encodes a set of compressed representations that describe it. Think of this as a fingerprint for each subject image and those with similar characteristics tend to usually have similar fingerprints. Below we show this latent space viewed in three dimensions where each dot represents one image. On the left, we’ve overlayed in pink images with Talk tags provided by volunteers, while on the right, we overlay the names of the Talk tags.
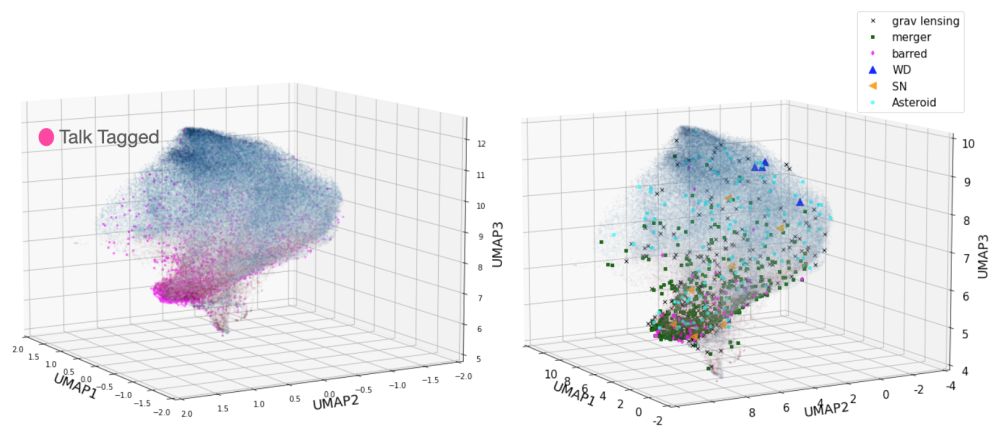
Interestingly, we find that a significant portion of the talk-discussed subjects cluster in a specific spot with respect to the overall distribution (i.e. their fingerprints are similar to each other but different from the rest of the galaxies that were inspected). We are currently investigating optimal strategies that would preferentially select talk-discussed subjects amongst the larger sample. This would provide us with a sample pre-selection process that can accelerate the finding of interesting and unusual subjects from a larger data set.
Finally, we are also very excited to report to you that a subset of the subjects (see examples below) that were tagged as being clumpy in nature have been successfully incorporated into an upcoming Hubble Space Telescope Gap-Filler proposal observations.

We are continuing our above analysis further and will post more on that in the near future!